


Article
How to Add Editable Areas to Exported MailChimp Templates
If you’ve tried recently exporting a MailChimp template you’ve been greeted with this alert. It’s...

Aug 15, 20142 min Read
Continue Reading

There seems to be a fair amount of confusion out there regarding what Google, Bing, and other search engines need to access in order to render your website properly.
A few weeks ago, Google began sending out messages to webmasters warning of important resources being blocked from the search engines.
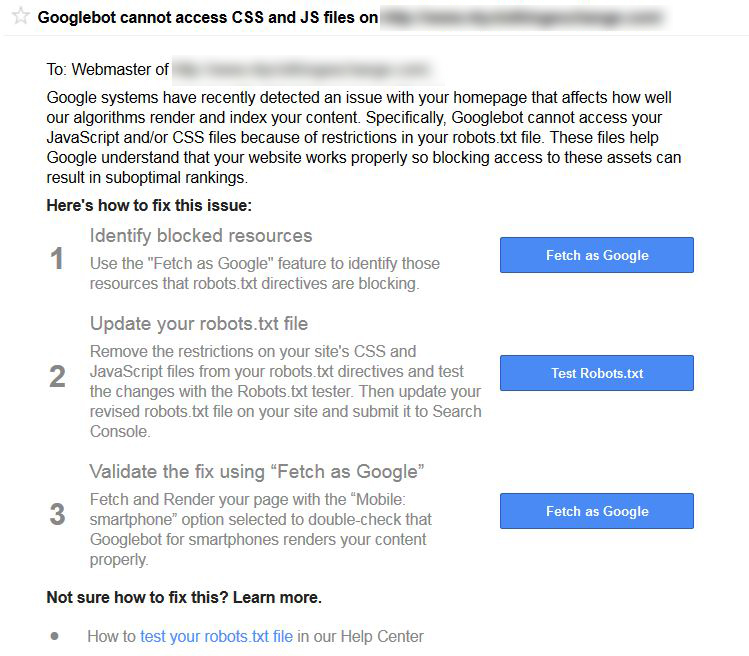
Here’s the deal: Google needs to see your JS and CSS files. If Google can’t see these files, Google can’t see your website. At least not the way you want Google to see your website.
Failure to give search engines access to these important files can result in this:
You probably know this by now, but if your website isn’t mobile friendly, you are less likely to rank well in search results. More importantly though, if your site doesn’t have the mobile-friendly icon in the search results and your competitors do, then you aren’t going to get the clicks.
It’s pretty simple. Don’t block CSS and JS from the search engines. The easiest way to do this is through your site’s robots.txt file. If you don’t have one, you need one right away.
The robots.txt file gives the search engines and other crawlers instructions about your website. The file should be located here: www.yoursite.com/robots.txt. If crawlers find nothing there, then they assume permission to crawl everything. They also may not know where to find your XML sitemap.
The key to keeping the crawlers happy is to give them access to everything they need to see your site. This includes all JS and CSS that’s required to make the site look how it should to your frontend users. This typically does not include all those JS and CSS files hiding in your site’s admin folders. Those are for you and your backend users. The search engines neither want nor need access (unless for some really strange reason you want your backend indexed). Of course, this only applies if your site is built properly. If you have important rendering files hiding in that admin folder, then you’ve got bigger problems on your hands.
You don’t want to overdo the robots.txt file. The more you jam into it, the more complicated things become for the crawlers. Your best bet is to restrict as little as possible. Yoast SEO, one of the most popular WordPress plugins in the world, goes as far as to tell you to leave the robots.txt file blank.
I wouldn’t recommend such an extreme action. Instead, here’s a basic robots.txt file that will make sure you aren’t hiding anything important:
User-agent: *
Disallow: /wp-admin/
Sitemap: http://www.website.com/sitemap_index.xml
User-agent: *
Allow: /
Sitemap: http://www.website.com/sitemap.xml
For WordPress sites, we used to have a laundry list of things we blocked from the crawlers. Now, we typically only disallow the admin folder. This prevents any bots from trying to enter into the folder (which they shouldn’t be able to do anyway). For most other sites, you won’t need to disallow anything.
It’s debatable whether you need to include your XML sitemap in the robots file. You should be submitting it directly to Google and Bing through Webmaster Tools. Still, it’s generally best practice to include this information in your robots.txt file in order to improve crawling and indexing.
If there are individual pages you want to exclude from the index, you shouldn’t do that through robots.txt. If you have an entire directory you don’t want the search engines to crawl, then it is only okay to disallow it in your robots file if there are no required JS or CSS files in that folder.
If you’re not sure what should be blocked or unblocked from the search engines, err on the side of caution. In this case, caution doesn’t mean trying to protect yourself against the big bad search engines. It’s better to let them crawl more than to prevent them from crawling something they need to evaluate your site. You can also have Google fetch your site in order to identify what necessary resources are being blocked.
Shortly after sending out the first wave of messages regarding the blocked CSS and JS, Google’s Gary Illyes suggested that the best solution was specifically to tell the search engines to crawl your CSS and JS files by doing this:
User-Agent: Googlebot
Allow: .js
Allow: .css
However, this solution doesn’t actually work if you have disallowed any of the folders that contain these files. For example, if you disallow /wp-includes/ and you have several important JS and CSS files in that directory, then Googlebot still isn’t going to get to them. The crawlers will obey the command to stay out of those folders before they’ll obey the command to look at those specific files. If you want the crawlers to see your CSS and JS (which you should), then you can’t settle for this method.
Also, it’s important to note that the robots file provides recommendations to crawlers. Google doesn’t have to follow these rules. More often than not, it will. If you tell it to stay out of a folder, it will. If you order it to do something else, it may listen (depending, of course, on what that order is).
No matter what you decide to include in your robots.txt file, the important thing is that you don’t restrict the search engines from being able to see those JS and CSS files. You may think you are saving crawls or protecting your site, but in reality you are just hurting yourself.
Nate Tower is the President of Perrill and has over 12 years of marketing and sales experience. During his career in digital marketing, Nate has demonstrated exceptional skills in strategic planning, creative ideation and execution. Nate's academic background includes a B.A. with a double major in English Language and Literature, Secondary Education, and a minor in Creative Writing from Washington University. He further expanded his expertise by completing the MBA Essentials program at Carlson Executive Education, University of Minnesota.
Nate holds multiple certifications from HubSpot and Google including Sales Hub Enterprise Implementation, Google Analytics for Power Users and Google Analytics 4. His unique blend of creative and analytical skills positions him as a leader in both the marketing and creative worlds. This, coupled with his passion for learning and educating, lends him the ability to make the complex accessible and the perplexing clear.

